Well that was fast. My last post described a project that analyzed word frequency in book titles, and mentioned that Google (which was providing the scanning and compiling for the project) had begun work on scanning and compiling an even larger corpus: the actual texts of every book published from 1500 to 2008. Now from the NY Times comes an article describing some preliminary analysis of the book text data sets. Even the preliminary results, obtained after only 11% of the task has been completed, are amazing.
[T]he researchers measured the endurance of fame, finding that written references to celebrities faded twice as quickly in the mid-20th century as they did in the early 19th. “In the future everyone will be famous for 7.5 minutes,” they write.
Looking at inventions, they found technological advances took, on average, 66 years to be adopted by the larger culture in the early 1800s and only 27 years between 1880 and 1920.
They tracked the way eccentric English verbs that did not add “ed” at the end for past tense (i.e., “learnt”) evolved to conform to the common pattern (“learned”). They figured that the English lexicon has grown by 70 percent to more than a million words in the last 50 years and they demonstrated how dictionaries could be updated more rapidly by pinpointing newly popular words and obsolete ones.
Other surprising and interesting facts mentioned include the relative frequencies of the words “men” and “women”, the popularity of Jimmy Carter, the rise of grilling, and the many more instances of the words “Tiananmen Square” in English-language texts than in Chinese-language texts.
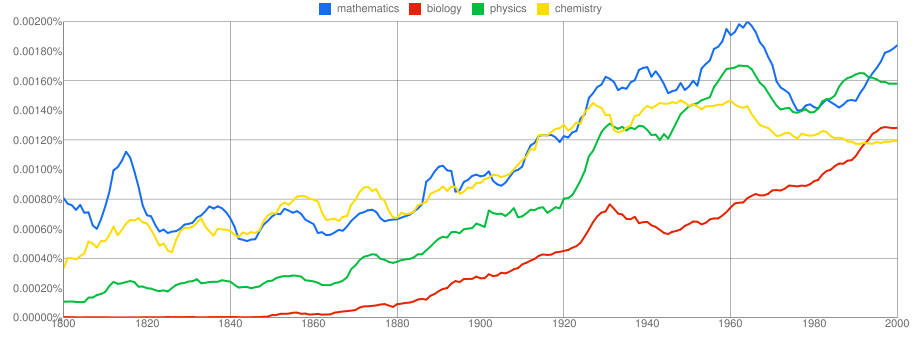
And there’s more! Google has created a web tool that lets anybody plot the popularity of words and phrases over time. In the picture heading this entry I charted the relative frequencies for the words “mathematics,” “biology”, “physics”, and “chemistry” for the years 1800–2000. I was a bit surprised (but not unhappy) to see mathematics leading the pack at the moment, but the thing that is most obvious is the general trend: people are just getting more and more interested in the sciences as time goes by. The article and the Google tool also mention that the data sets themselves are available for download for those who have more heavy-duty data analysis in mind.
The research is detailed in a recent article from Science, which has taken the unusual step of making the article freely available. (That’s what the Times article says. It looks to me like you do have to sign up for a free Science registration.) Fourteen entities collaborated on the project; I use the word ‘entities’ because one author is listed as “The Google Books Team.” The two main authors, Jean-Baptiste Michel and Erez Lieberman Aiden, both have backgrounds in applied mathematics, as do some of the other listed authors.
As with the previous work on title words, the reaction of humanities scholars to the appearance of statistics and data analysis in their domain has been mixed. But there seems to be little doubt that, as the article states, this data set itself “offers a tantalizing taste of the rich buffet of research opportunities now open to literature, history and other liberal arts professors who may have previously avoided quantitative analysis.”