The first paragraphs of newspaper articles typically aim to summarize the main points of the full article, and the first paragraph of this NY Times article by Patricia Cohen does a whiz-bang job.
Victorians were enamored of the new science of statistics, so it seems fitting that these pioneering data hounds are now the subject of an unusual experiment in statistical analysis. The titles of every British book published in English in and around the 19th century — 1,681,161, to be exact — are being electronically scoured for key words and phrases that might offer fresh insight into the minds of the Victorians.
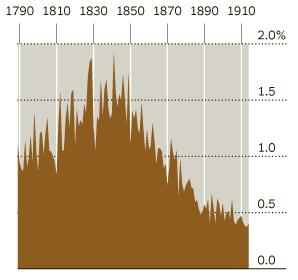
The data comes from a project of Dan Cohen and Fred Gibbs, Victorian scholars at George Mason University, with a big assist from Google, which is funding the project and carrying out the scanning and compiling. Although only the titles of the books have been compiled to date, even they reveal some interesting trends. The image above is one of a few graphs generated by the Times from the title data, and shows a big decline in the appearances of the word “Christian” in titles as the 19th century progressed. Other graphs show big decreases in the use of “universal”, and increases in the instances of the words “industrial” and “science”.
The entire corpus—the text of the books as well as the titles—should be compiled soon, at which point more sophisticated analyses can be performed. The quoted reactions of Victorian scholars toward the appearance of statistical tools in their milieu vary from “sheer exhilaration” to “excited and terrified”. But one common reaction to the analysis seems pervasive, and was best expressed by Matthew Bevis, a lecturer at the University of York in Britain: “This is not just a tool; this is actually shaping the kind of questions someone in literature might even ask.”