In order to properly assign random identification numbers to those who contributed specific sets of data. I truly wanted randomly computer-generated numbers not just a 1-10 count. However, I did not know how to ask Excel to do this for me, so I consulted the internet. I googled “randomly generated numbers excel” and got a few promising articles and set to work learning. One of the best videos I found was from a youtuber known as Doug H. who specializes in excel and its functions, he is amazing! What most of the articles asked was to use the (=RAND) command which I found worked perfectly to generate a single random number, however I needed a lot more. Since the function needed a number minimum and maximum, I went with the classic 1-100; (=RANDBETWEEN(1,100)).
Microsoft Excel
My Opinion: The Best and Worst Functions of Excel for this Project

When creating our database, we had to input a large amount of information into each column for each index card. In this, I love the simple yet amazing ability to freeze the first row of the spreadsheet. Of course, the same can be done for columns.Whether we were on index card 2, 20, or 120, we could clearly see the column title of what type of information we were inputting.
Another function of excel that was awesome was the use of pivot tables. Pivot tables allowed us to quickly sort and count our data to give us an idea of what our data would look like once uploaded for data visualization. For instance, with a pivot table we could see how many speakers were attributed to each language. We could also see who input what data, and sort by what type of information. For example, if one of the team member had clacked on my name, they could see how many cards I input were English. However, we decided not to keep it as part of our data set as the external visualization program we used allowed us to see the same information when we uploaded our data, even allowing clickable charts, maps, etc.
A final function that was greatly appreciated was the ability of an Excel spreadsheet to be uploaded onto Google drive, shared, then downloaded as an Excel file. This helped greatly, as the team felt most comfortable with Excel over the Google spreadsheet. Though I’m not sure if this should be attributed to Google or Microsoft (or both), this was none the less a great function.
But with the best, also comes the worst…

The biggest problem for me when starting this project was using qualitative data as opposed to quantitative data. When I had previously learned how to use an earlier version of Microsoft Excel early in high school, we worked with quantitative data and functions. In that, I found it a bit challenging in the beginning to just be putting in names and words instead of mathematical problems and functions. However, I was surprised to find that when working in a column, excel will pop up with a cell fill-in for a word previously used. So say I was typing in the last name ‘Smith’ for a second or fifth time, I would have only typed up to the ‘m’ and excel would suggest “Smith” to put into the cell.

Where this turns sour for me is that if you skip a cell down and start typing into the second cell underneath, it no longer has the fill in as an option. I REALLY wish that this carried over while in the same column. When it came to really long or odd names, I really wished that excel would still automatically suggest a word fill in, even when you skip the cell of the next row. 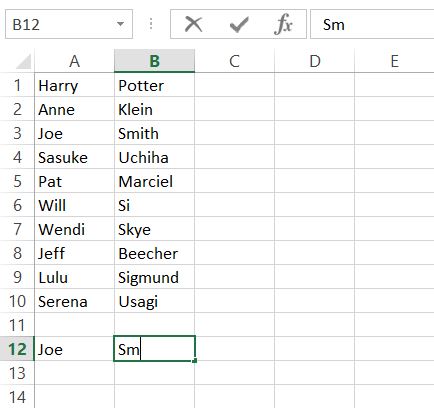
When trying to visualize our data, we ran into a problem. Where we had input just countries or regions (i.e. Atlantic Midland, Inland North, etc.) as the language’s origin, the visualization technology we were using could not figure out how to map the languages with just the country. In that, we had to go back and put in the capital of each country of the languages origin, and designate a ‘capital’ for different types of English (i.e. North Jersey vs. South Jersey English), which resulted in a more accurate depiction of the locations of each language origin. Overall, I wish that Microsoft Excel would improve on it’s compatibility with other software and websites. Though I understand there’s much time, thought, and agreement that needs to be done for this, companies like Amazon and Paypal work with other websites and services to create a smoother use of services. Therefore, Microsoft does have the ability to work better with other companies’ programs, and I wish that both parties would work to do so in the near future.
Both of the above images do not belong to me. ‘Spirited Away’ is the property of Studio Ghibli/Disney and were found here: giphy.com/search/spirited-away-gif
Building our Site
When deciding what pages to include in our Menu, I had to really think about what pages are on regular websites. I decided that Our Mission Statement should be a our homepage so that when you arrive at our site, you know about our project and our goals. I revised the mission statement several times and finally decided upon the finished product you see now.
My second thought was having a page explaining what exactly we mean by Language Maps and Language Clouds. Dr. Quizon thankfully authored this page with working links.
As a team, we decided to rename the blog page to “The Project”. This was a unanimous decision. We wanted to take people step by step through our process.
Our “Contact Us” page is for anyone who has questions, comments, or wants to use our research which is covered by Creative Commons. The “Contribute” page will be an open forum for anyone who would like to add their languages to our research. We are working now with a WordPress expert who is going to build our questionnaire which will input directly into an Microsoft Excel spread sheet, already coded.
We encourage you to check back soon and contribute your own languages!
Using Viewshare
ViewShare is a website in which people can input a selection of data, like an excel chart, and the program will allow the person to create different charts, maps, lists and timelines, depending on what kind of information the program can read from the data. Professor Quizon set up the account and I, Ellie Hautz, explored it’s features with a mock Microsoft Excel spreadsheet to see how we could use ViewShare in our research. We all worked on coding the information onto the Microsoft Excel file. I took the final version and uploaded it to ViewShare to see what I could do with it. I was so excited to see the amount of charts I could make with it. I looked at the map portion and it had plotted points that I had not intended it to. For instance our version of New York was specifying New York, NY. However, the program read it as New York in the United Kingdom. So I thought that maybe putting in coordinates would plot easily. I then had a discussion with the group to decided what coordinates we were going to use. We decided that for everyone using North New Jersey English would be based on Bergen County and South New Jersey English would be Cape May County since they were the most coastal north and the most coastal south.The majority of our participants were from New Jersey. However, a good deal of participants indicated other states our countries. For plotting these, we decided to use the capital of the state or country origin of the language unless otherwise specified by the participant. So I made an extra section of my own Microsoft Excel spreadsheet with the coordinates for these areas, however, it still was not working properly. I looked closely and the program asked for the city and state and/or country of each data point. So I went through again and used the capital of every county, state, and country. Finally it worked and the map plotted correctly.
Unfortunately, after a week or so of the corrected data, ViewShare stopped being compatible with our first set of data.
Microsoft Excel: Randomized Number I.D. for Participants
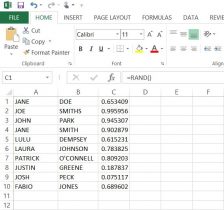
In order to present our data by the participant, the ethical thing was to avoid revealing the actual name of the individuals who gave us our data. In this, we used Microsoft Excel to generate and assign random numbers, rather than simply numbering every subject individually. These numbers would then act as the I.D.’s for each participant. On a separate spreadsheet, we put participants first and last names in columns ‘A’ and ‘B’ respectively (here I have put in ten fake names* to show you an example). For our data, we had a list of all the participants’ names in alphabetical order by last name.

Next, I used the RAND, or random function. By putting the =RAND() function into column ‘C’ from cells C1 to C10, we were given a random decimal number. Then, I had tried to use the =RANDBETWEEN function in column ‘D’, inputting =RANDBETWEEN(1,10). Although this gave us a random whole number between 1 and 10, there were repeats of the same number. So now one of the biggest problems was finding a way to have excel create random intergers that did NOT repeat.
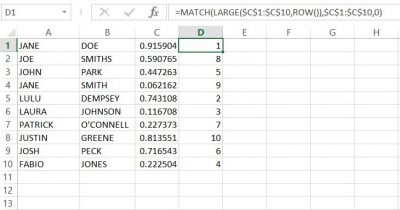
Finally, with a little help from the library and the internet, I used the following formula to generate NON-REPEATING whole numbers in column ‘D’;
=MATCH(LARGE($C$1:$C$20,ROW()),$C$1:$C$20,0)
The result was what we were looking for, anonymity for our participants. With this success, we copied and pasted the numbers next to the names in the list of participants in our data set.**
*None of these names are meant to have any relation to any person(s) alive or deceased.
**When I input the function into column ‘D’, the random values in column ‘C’ changed automatically, but remained random. you need to keep this formula in this column in order for the function in ‘D’ to work.
There may be other ways of achieving the same outcome, but this formula worked best in excel.
Our Naming Convention and Communication
All data we entered had to not only be divided evenly among the team, but it also needed to be checked to make sure that the information is correct and who had last saved the data. We agreed to use an author naming convention by using our initials. In the Microsoft Excel spreadsheets, we designated four additional columns for this purpose, and two more columns were added to communicate on the spreadsheet itself. Columns D,E, R, S, T, and U were used for the following: D was ‘Entered by CQ/MP/AB/EH’, E was ‘Date Entered’, R was ‘Comments’, S was ‘Checked by CQ/MP/AB/EH’, T was ‘Date Checked’, and U was ‘Additional Notes’. The ‘Comments’ column was used to communicate changes to data. Say I had entered a name wrong as ‘McThomas’, but Michelle caught the mistake, and would write in that row under column R ‘MP-AB fixed last name to MacThomas’. This tells us that Michelle is writing to Anastasia (me) that she fixed the error in the last name I made. If we had a question or were not sure of a data entry or part of one, we would write in column R as well. For example, if Ellie had a question about a missing name, she could write in the ‘Comments’ column ‘Which participant is this?’ or simply state ‘No name given’.
The initial convention was used not only to show who input and checked the data, but also who had last saved the data. To give an example, if I was the first to put in data, I would label the newly saved excel sheet ‘AB Raw Data Set 1’. If Ellie was the next to input her data and check mine, the new excel sheet would be titled and saved as ‘AB-EH Raw Data Set 1’. Then, if Michelle were to do the same, the file would be saved as ‘AB-EH-MP Raw Data Set 1’. This naming method would continue until all data is input and checked.
Overall, this system of using our initials to know who last saved, checked, and input data worked very well. It was a simple, clear way to know among the team who had last saved the most recent data and who was communicating with who within the spreadsheet, especially between meetings.
The Origin of the Project
In the Fall 2015 Linguistic Anthropology class taught by Dr. Quizon, students were asked to share information about any and all languages that they knew. She gave out note cards and instructed the class to write down one language per card. Underneath the name of the language, they were asked to write down anything they wished to say about this language. They used descriptors of their own design making these cards rich with open-ended qualitative data. On the reverse of each card, they were asked to write their names.
With support from Seton Hall’s Digital Humanities Fellowship initiative, Dr. Quizon and three student interns who completed the course in the previous semester took a closer look at this data and explored ways to visualize the information. Were there intriguing or interactive ways to plot linguistic information? Could the data be mapped? Were there patterns to be discovered when expressed in visual form?
The class of 35 students was surveyed twice: once in the beginning of the semester, and again towards the end of the semester. The Language Maps, Language Clouds research team took these two sets of note cards, devised ways to capture, organize and analyze the information using linguistic concepts, explored ways to visualize the results of our queries, and aimed to share our findings online. Our goal is to share both processes and results as we seek to deepen our understanding of the data an interesting, interactive setting.
Even though we all participated in every aspect of the project, we each had an area of expertise. Ellie learned how to use and troubleshoot Viewshare and later, with Dr. Quizon, explored Tableau. She worked with Anastasia who was in charge of Excel and added knowledge of its features as needed for the project. I was in charge of learning how to build a blog on WordPress.