When deciding what pages to include in our Menu, I had to really think about what pages are on regular websites. I decided that Our Mission Statement should be a our homepage so that when you arrive at our site, you know about our project and our goals. I revised the mission statement several times and finally decided upon the finished product you see now.
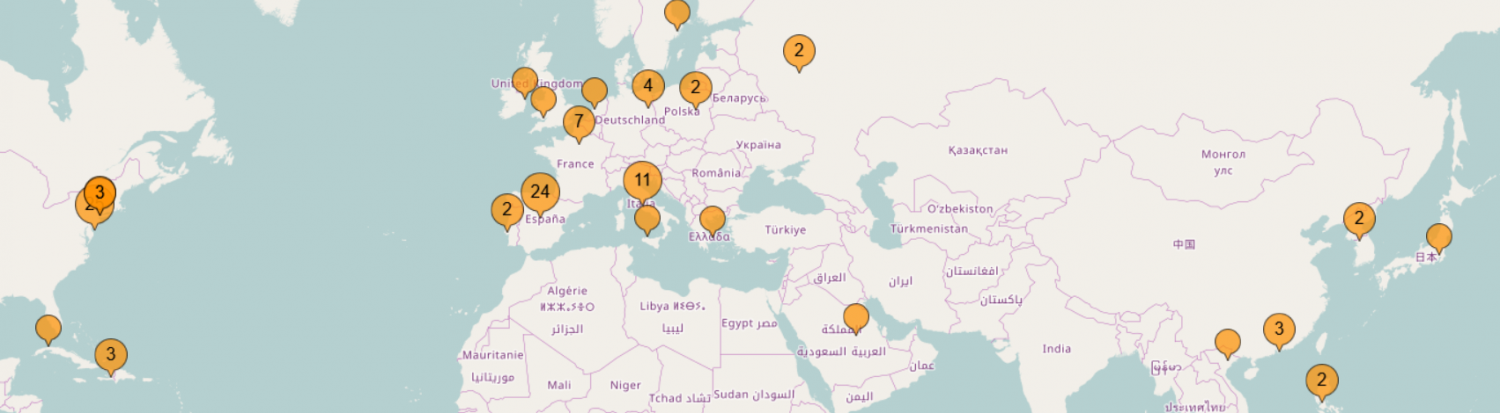
My second thought was having a page explaining what exactly we mean by Language Maps and Language Clouds. Dr. Quizon thankfully authored this page with working links.
As a team, we decided to rename the blog page to “The Project”. This was a unanimous decision. We wanted to take people step by step through our process.
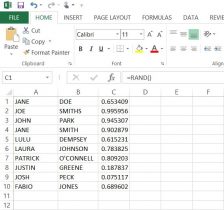
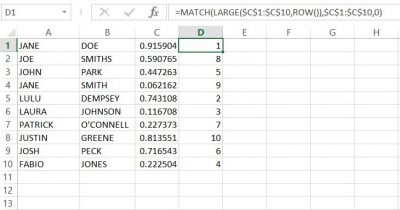
Our “Contact Us” page is for anyone who has questions, comments, or wants to use our research which is covered by Creative Commons. The “Contribute” page will be an open forum for anyone who would like to add their languages to our research. We are working now with a WordPress expert who is going to build our questionnaire which will input directly into an Microsoft Excel spread sheet, already coded.
We encourage you to check back soon and contribute your own languages!