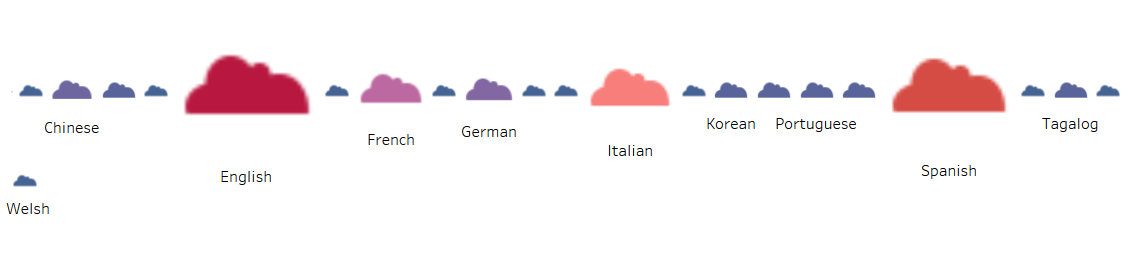
As of July, our research interns officially began coding the data extracted from the note cards.
The first step was moving all the raw data information from the individual note cards to an Excel spreadsheet. Once we finished transcribing the data verbatim from the cards, we noticed that the individual descriptors on each card would make coding the spreadsheet difficult. What undoubtedly made the cards unique, also made them so versatile that coming up with a coding system would be an ambitious task. We wanted to keep the authenticity of the raw data while also coding the entries in an easily understood manner, making it significantly easier for us to plot.
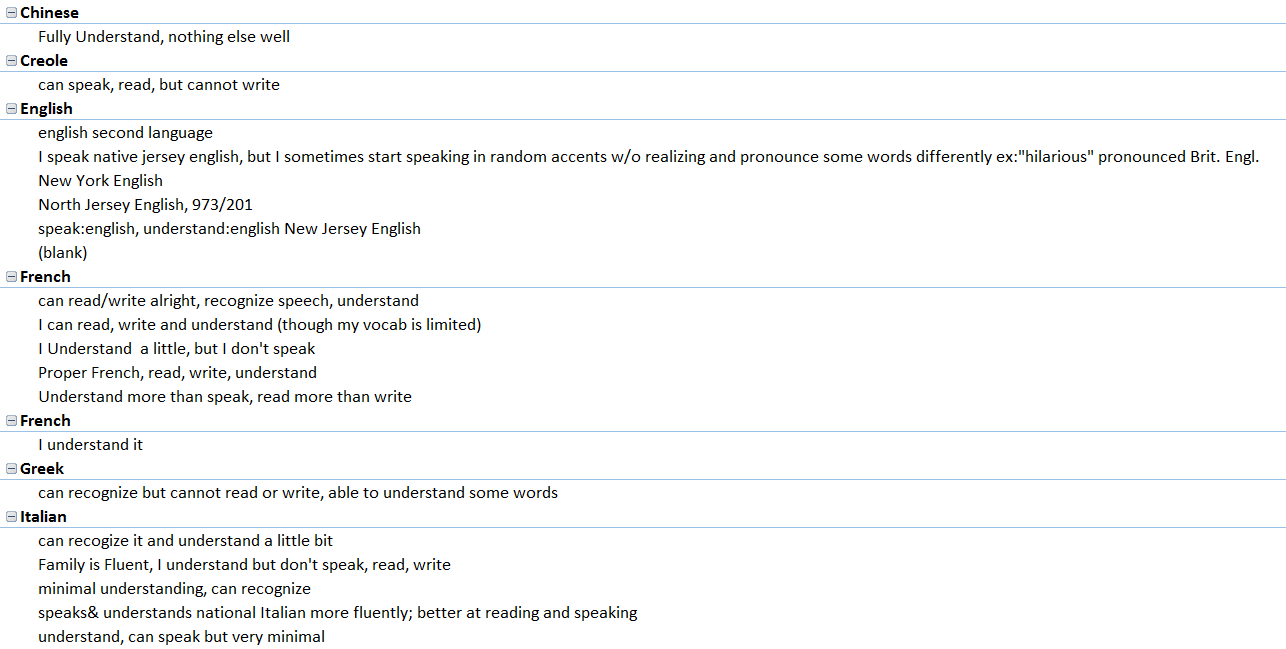

[box] Here are the unique descriptors that students wrote on their note cards. [/box]
Before establishing the coding system, we had to answer some questions: If the language is Spanish, but the card identifies The Dominican Republic or Puerto Rico, do we code that region as Spain or as the other two countries? What can we assume from the cards if we can assume anything? Since each research intern takes part in all steps of the process, establishing a concise coding system is essential so that every card is coded the same way.
Generally, the beginning of our research meetings are spent discussing any coding problems that come up. We are currently still coding the First Data Set and have started coding the Second Data Set.