In working with Nathan Kahl on his Digital Humanities Faculty Fellows project, I came across an online service from Meaning Cloud that was really helpful. Here’s a primer on how you can get started, and some of the kinds of results you can get back from it.
Besides simple web forms to process pieces of text, they offer a whole set of APIs that let you automate the process for larger sets. Nate’s project, for example, used the lyrics of 4,000 popular songs. And in addition to the APIs themselves, they have sample code that helps you cut through the hard-for-humans-to-read XML or JSON results.
The kinds of processing you can do include topics extraction, text classification, sentiment analysis, language identification, lemmatization part-of-speech and parsing, corporate reputation and text clustering.
Getting Started
You’ll need to open an account. The basic level is free, and it gives you something like 40,000 individual submissions per month. You’ll get a logon and password, and also an API key which you will use in all your requests. Be sure to copy it someplace safe! Once you have it, you can right away start to work with some sample texts.
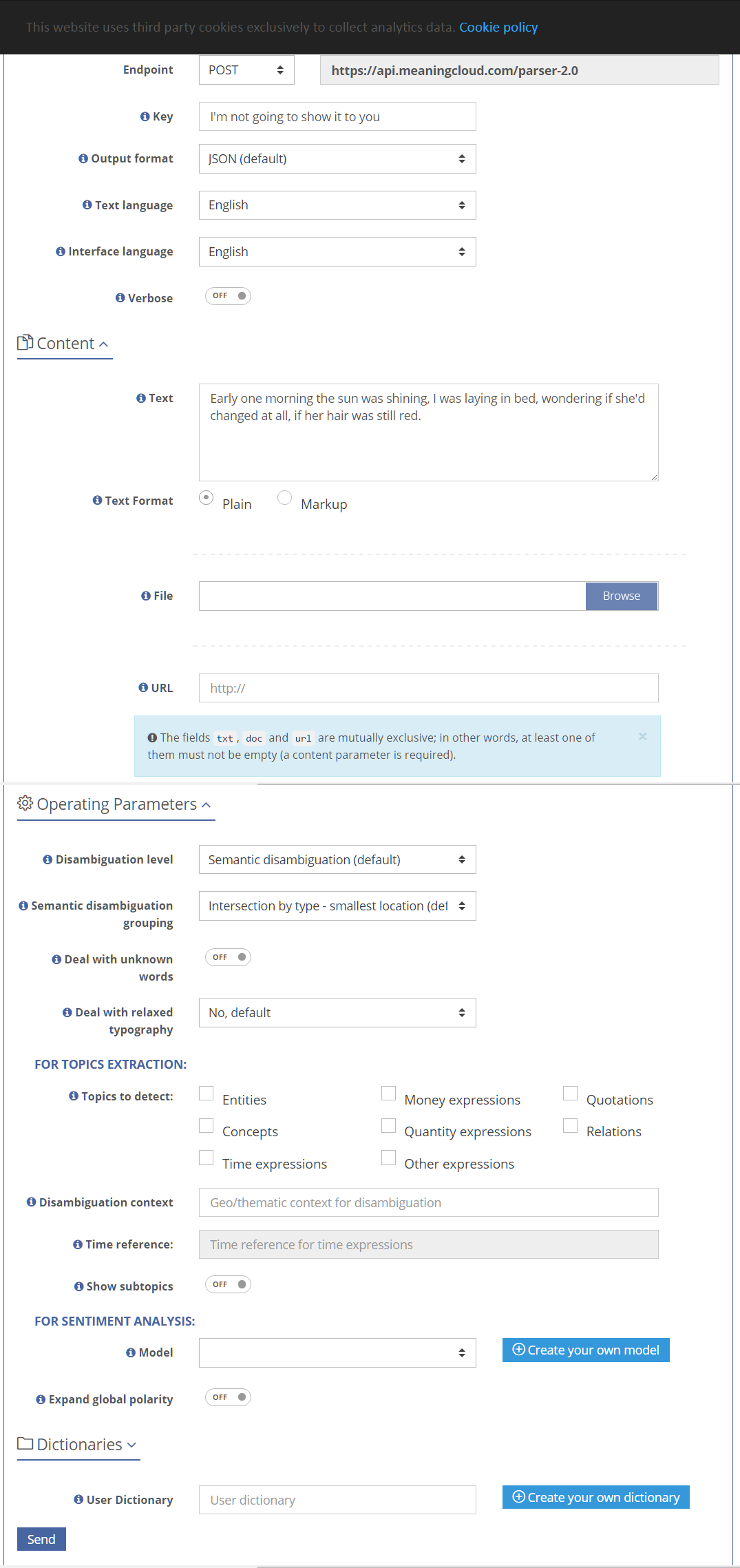
For Example
Lemmatization, POS and parsing was the most relevant tool for our project, which involved simple word counts (similar to n-grams) in Billboard top-100 songs over a 40 year period. Let’s take a small excerpt from a song, which should fit in under fair use, and run it through the processor.
Mostly you can get by with the default settings. But you’ll need to specify your key, output format, language and text. You can paste your text in, as I did, upload a file, or point to a URL.
I’ve gone with a JSON result, because it’s easy to use with PHP, JavaScript and other tools. The result is what in programming language is called an “array.”
If you want to go in for a deep dive, the resulting array is here; but let’s break out a few sections so you can see what you’re getting.
The text is split up into “tokens,” which is exactly what we needed. Top level tokens are sentences, second level tokens are phrases, and finally you get down to the level of an individual word. (This explanation is all a really simple gloss of course; language processing is quite complex and I don’t pretend to understand more than a fraction of it.) The array contains the type (phrase, sentence) along with the form (the original text). Formatting is indicated — if the original was bold, italic, underlined, or a title — whether it’s affected by a negation, and each atom gets an ID number so you can reference them.
This is a result for the first word, “early.”
token_list: [
{
form: "Early",
id: "1",
inip: "0",
endp: "4",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "_",
quote_level: "0",
affected_by_negation: "no",
analysis_list: [
{
tag: "ENMPN6",
lemma: "early",
original_form: "early"
}
]
}
]
The part we were interested in is at the end, where we get the tag, lemma and original form.
The tag is a coding of the type of speech and context of the word. The lemma is similar to word-stemming, the difference being that instead of just capturing “big,” “bigger” and “biggest” as forms of the same word it also captures “good,” “better” and “best.” Or verb forms like “was shining” reduce down to “shine.” All three of these go into our database.
The individual characters of the tags correspond to a morphosyntactic tagset. So we can look up our tag for “early” and derive the following:
- E
- Adverb
- N
- Normal
- M
- Adverb of manner
- P
- Positive
- N
- Normal word
- 6
- Medium-high frequency
In a similar way it analyzes the individual clauses or phrases. So “wondering if she’d changed at all” returns a tag of “ZA—XPP—-“, which can be analyzed from the clause table as:
- Z
- Clause
- A
- Adjectival
- –
- Gender (not applicable in this case)
- –
- Number (also not applicable)
- –
- Person (n/a)
- X
- Syntactic Function (in this case, Non-restrictive apposition)
- P
- Mode (participle)
- P
- Tense (past)
- –
- n/a
- –
- n/a
- –
- n/a
- –
- n/a
As you browse the code tables you see there’s a very rich analysis available.
The database stores the song titles, years, performers, and chart position; as well as a table of words; a table that maps words to songs along with a total count for each; the same for lemmas; and the same for tags. Using these indexed tables you can search very quickly for the cumulative data.
What Does All This Do?
Our first implementation was a page that graphs the frequency of usage for words, year-by-year, over the 40 year period from 1960 to 2000. Here’s an example, comparing the number of songs that used “man” and “woman”:
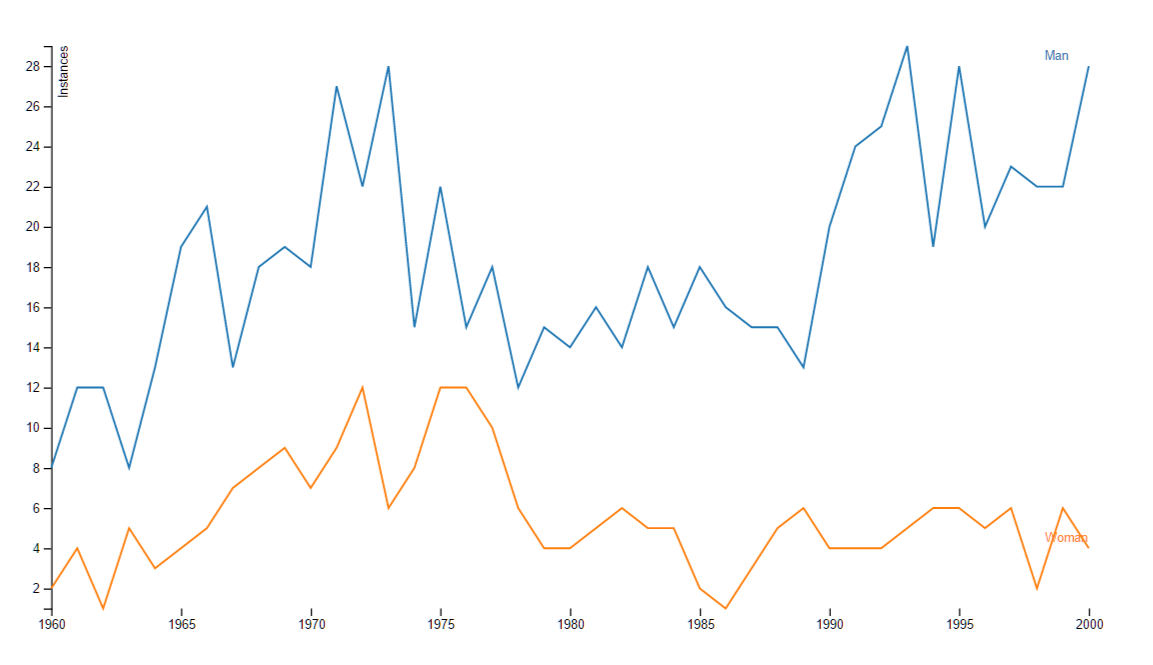
You can also get the number of times in total the words were used:

Wasn’t it James Brown who said, “it’s a man’s world?” But I digress.
There is another version that also returns a table, which you could import into Excel and do further analysis.
Another view shows you the lemmatization of a word, in this case, all the various word-forms for “love.”

You can play with the whole package on the project page. There are also a couple of APIs that return the song counts along with a list of the songs where the word is used.
Meaning Cloud’s JSON Return Array
{
status: {
code: "0",
msg: "OK",
credits: "1",
remaining_credits: "39993"
},
token_list: [
{
type: "sentence",
id: "36",
inip: "0",
endp: "120",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "A",
quote_level: "0",
affected_by_negation: "no",
token_list: [
{
type: "phrase",
form: "Early one morning the sun was shining, I was laying in bed, wondering if she'd changed at all, if her hair was still red",
id: "53",
inip: "0",
endp: "119",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "_",
quote_level: "0",
affected_by_negation: "no",
analysis_list: [
{
tag: "Z-----------",
lemma: "*",
original_form: "Early one morning the sun was shining, I was laying in bed, wondering if she'd changed at all, if her hair was still red"
}
],
token_list: [
{
type: "phrase",
form: "Early",
id: "49",
inip: "0",
endp: "4",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "_",
quote_level: "0",
affected_by_negation: "no",
head: "1",
syntactic_tree_relation_list: [
{
id: "35",
type: "isMannerComplement"
}
],
analysis_list: [
{
tag: "GEM--M--",
lemma: "early",
original_form: "Early"
}
],
token_list: [
{
form: "Early",
id: "1",
inip: "0",
endp: "4",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "_",
quote_level: "0",
affected_by_negation: "no",
analysis_list: [
{
tag: "ENMPN6",
lemma: "early",
original_form: "early"
}
]
}
]
},
{
type: "phrase",
form: "one morning",
id: "39",
inip: "6",
endp: "16",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
head: "3",
syntactic_tree_relation_list: [
{
id: "35",
type: "isTimeComplement"
}
],
analysis_list: [
{
tag: "GN-S3T--",
lemma: "morning",
original_form: "one morning"
}
],
token_list: [
{
form: "one",
normalized_form: "numeric@1",
id: "2",
inip: "6",
endp: "8",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
analysis_list: [
{
tag: "MD-SCN7",
lemma: "one",
original_form: "one",
sense_id_list: [
{
sense_id: "e01b5f50fb"
}
]
}
],
sense_list: [
{
id: "e01b5f50fb",
form: "one",
info: "sementity/class=class@fiction=nonfiction@id=ODENTITY_NUMEX@type=Top>Numex semld_list=sumo:Quantity"
}
]
},
{
form: "morning",
id: "3",
inip: "10",
endp: "16",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
analysis_list: [
{
tag: "NC-S-N6",
lemma: "morning",
original_form: "morning"
}
]
}
]
},
{
type: "phrase",
form: "the sun",
normalized_form: "date@|||d|||||||",
id: "40",
inip: "18",
endp: "24",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
head: "5",
syntactic_tree_relation_list: [
{
id: "35",
type: "isSubject"
},
{
id: "45",
type: "iof_isAnaphora"
},
{
id: "42",
type: "iof_isPossessor"
}
],
analysis_list: [
{
tag: "GN-S3S--",
lemma: "sun",
original_form: "the sun"
}
],
token_list: [
{
form: "the",
id: "4",
inip: "18",
endp: "20",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
analysis_list: [
{
tag: "TD-SN9",
lemma: "the",
original_form: "the"
}
]
},
{
form: "sun",
normalized_form: "date@|||d|||||||",
id: "5",
inip: "22",
endp: "24",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
analysis_list: [
{
tag: "NC-S-N5",
lemma: "sun",
original_form: "sun",
sense_id_list: [
{
sense_id: "2245de2af4"
}
]
}
],
sense_list: [
{
id: "2245de2af4",
form: "sun",
info: "sementity/class=class@fiction=nonfiction@id=ODENTITY_ASTRAL_BODY@type=Top>Location>AstralBody semld_list=sumo:AstronomicalBody semtheme_list/id=ODTHEME_ASTRONOMY@type=Top>NaturalSciences>Astronomy"
}
]
}
]
},
{
type: "multiword",
form: "was shining",
id: "35",
inip: "26",
endp: "36",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
head: "6",
syntactic_tree_relation_list: [
{
id: "49",
type: "iof_isMannerComplement"
},
{
id: "39",
type: "iof_isTimeComplement"
},
{
id: "40",
type: "iof_isSubject"
}
],
analysis_list: [
{
tag: "VI-S3ACA-N-N9",
lemma: "shine",
original_form: "was shining"
}
]
},
{
form: ",",
id: "8",
inip: "37",
endp: "37",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "A",
quote_level: "0",
affected_by_negation: "no",
analysis_list: [
{
tag: "1D--",
lemma: ",",
original_form: ","
}
]
},
{
type: "phrase",
form: "I",
id: "46",
inip: "39",
endp: "39",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
head: "9",
syntactic_tree_relation_list: [
{
id: "27",
type: "isSubject"
},
{
id: "34",
type: "isSubject"
}
],
analysis_list: [
{
tag: "GN-S1S--",
lemma: "I",
original_form: "I"
}
],
token_list: [
{
form: "I",
id: "9",
inip: "39",
endp: "39",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
analysis_list: [
{
tag: "PP-S1NN-",
lemma: "I",
original_form: "I",
sense_id_list: [
{
sense_id: "PRONHUMAN"
}
]
}
],
sense_list: [
{
id: "PRONHUMAN",
form: "I",
info: "semhum=human"
}
]
}
]
},
{
type: "multiword",
form: "was laying",
id: "34",
inip: "41",
endp: "50",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
head: "10",
syntactic_tree_relation_list: [
{
id: "46",
type: "iof_isSubject"
},
{
id: "48",
type: "iof_isComplement"
},
{
id: "50",
type: "iof_isComplement"
}
],
analysis_list: [
{
tag: "VI-S1ACA-N-N9",
lemma: "lay",
original_form: "was laying"
}
]
},
{
type: "phrase",
form: "in bed, wondering if she'd changed at all",
id: "48",
inip: "52",
endp: "92",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
head: "12",
syntactic_tree_relation_list: [
{
id: "34",
type: "isComplement"
},
{
id: "48",
type: "isNonRestrictiveApposition"
},
{
id: "48",
type: "iof_isNonRestrictiveApposition"
}
],
analysis_list: [
{
tag: "GY---C--",
lemma: "in",
original_form: "in bed"
}
],
token_list: [
{
form: "in",
id: "12",
inip: "52",
endp: "53",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
analysis_list: [
{
tag: "YN6",
lemma: "in",
original_form: "in"
}
]
},
{
type: "phrase",
form: "bed",
id: "41",
inip: "55",
endp: "57",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
head: "13",
analysis_list: [
{
tag: "GN-S3---",
lemma: "bed",
original_form: "bed"
}
],
token_list: [
{
form: "bed",
id: "13",
inip: "55",
endp: "57",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
analysis_list: [
{
tag: "NC-S-N6",
lemma: "bed",
original_form: "bed",
sense_id_list: [
{
sense_id: "19b7b05b8c"
}
]
}
],
sense_list: [
{
id: "19b7b05b8c",
form: "bed",
info: "sementity/class=class@fiction=nonfiction@id=ODENTITY_CHANNEL@type=Top>Location>GeographicalEntity>WaterForm>Channel semld_list=sumo:Channel"
}
]
}
]
},
{
form: ",",
id: "14",
inip: "58",
endp: "58",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "A",
quote_level: "0",
affected_by_negation: "no",
analysis_list: [
{
tag: "1D--",
lemma: ",",
original_form: ","
}
]
},
{
type: "phrase",
form: "wondering if she'd changed at all",
id: "52",
inip: "60",
endp: "92",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
analysis_list: [
{
tag: "ZA---XPP----",
lemma: "*",
original_form: "wondering if she'd changed at all"
}
],
token_list: [
{
form: "wondering",
id: "15",
inip: "60",
endp: "68",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
syntactic_tree_relation_list: [
{
id: "51",
type: "iof_isComplement"
}
],
analysis_list: [
{
tag: "VP---PSA-N-N4",
lemma: "wonder",
original_form: "wondering",
sense_id_list: [
{
sense_id: "ODENTITY_INTENTIONAL_PSYCHOLOGICAL_PROCESS"
}
]
}
],
sense_list: [
{
id: "ODENTITY_INTENTIONAL_PSYCHOLOGICAL_PROCESS",
form: "wonder",
info: "sementity/id=ODENTITY_INTENTIONAL_PSYCHOLOGICAL_PROCESS@type=Top>Process>IntentionalProcess>IntentionalPsychologicalProcess semld_list=sumo:IntentionalProcess"
}
]
},
{
type: "phrase",
form: "if she'd changed at all",
id: "51",
inip: "70",
endp: "92",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
syntactic_tree_relation_list: [
{
id: "15",
type: "isComplement"
}
],
analysis_list: [
{
tag: "ZE---CIA----",
lemma: "*",
original_form: "if she'd changed at all"
},
{
tag: "ZE---CO-----",
lemma: "*",
original_form: "if she'd changed at all"
},
{
tag: "ZE---CC-----",
lemma: "*",
original_form: "if she'd changed at all"
},
{
tag: "ZE---CA-----",
lemma: "*",
original_form: "if she'd changed at all"
},
{
tag: "ZE---CO-----",
lemma: "*",
original_form: "if she'd changed at all"
},
{
tag: "ZE---CC-----",
lemma: "*",
original_form: "if she'd changed at all"
}
],
token_list: [
{
form: "if",
id: "16",
inip: "70",
endp: "71",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
analysis_list: [
{
tag: "CSBN7",
lemma: "if",
original_form: "if"
}
]
},
{
type: "phrase",
form: "she",
id: "45",
inip: "73",
endp: "75",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
head: "17",
syntactic_tree_relation_list: [
{
id: "40",
type: "isAnaphora"
},
{
id: "33",
type: "isSubject"
}
],
analysis_list: [
{
tag: "GNFS3S--",
lemma: "she",
original_form: "she"
}
],
token_list: [
{
form: "she",
id: "17",
inip: "73",
endp: "75",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
analysis_list: [
{
tag: "PPFS3NN8",
lemma: "she",
original_form: "she",
sense_id_list: [
{
sense_id: "PRONHUMAN"
}
]
}
],
sense_list: [
{
id: "PRONHUMAN",
form: "she",
info: "semhum=human"
}
]
}
]
},
{
type: "multiword",
form: "'d changed",
id: "33",
inip: "76",
endp: "85",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "A",
quote_level: "0",
affected_by_negation: "no",
head: "32",
syntactic_tree_relation_list: [
{
id: "45",
type: "iof_isSubject"
},
{
id: "47",
type: "iof_isComplement"
},
{
id: "50",
type: "iof_isComplement"
}
],
analysis_list: [
{
tag: "VI-UUASA-N-E-",
lemma: "change",
original_form: "'d changed"
},
{
tag: "VI-UUCSA-N-E8",
lemma: "change",
original_form: "'d changed"
},
{
tag: "VW-UUOSA-N-E7",
lemma: "change",
original_form: "'d changed"
}
]
},
{
type: "phrase",
form: "at all",
id: "47",
inip: "87",
endp: "92",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
head: "21",
syntactic_tree_relation_list: [
{
id: "33",
type: "isComplement"
}
],
analysis_list: [
{
tag: "GY---C--",
lemma: "at",
original_form: "at all"
}
],
token_list: [
{
form: "at",
id: "21",
inip: "87",
endp: "88",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
analysis_list: [
{
tag: "YN8",
lemma: "at",
original_form: "at"
}
]
},
{
type: "phrase",
form: "all",
id: "44",
inip: "90",
endp: "92",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
head: "22",
analysis_list: [
{
tag: "GN--3---",
lemma: "all",
original_form: "all"
},
{
tag: "GN-S3---",
lemma: "all",
original_form: "all"
},
{
tag: "GN-P3---",
lemma: "all",
original_form: "all"
}
],
token_list: [
{
form: "all",
id: "22",
inip: "90",
endp: "92",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
analysis_list: [
{
tag: "QP--PN6",
lemma: "all",
original_form: "all"
},
{
tag: "QP-SPN6",
lemma: "all",
original_form: "all",
sense_id_list: [
{
sense_id: "PRONNONHUMAN"
}
]
},
{
tag: "QP-PPN6",
lemma: "all",
original_form: "all",
sense_id_list: [
{
sense_id: "PRONNONHUMAN"
}
]
}
],
sense_list: [
{
id: "PRONNONHUMAN",
form: "all",
info: "semhum=nonhuman"
}
]
}
]
}
]
}
]
}
]
}
]
},
{
form: ",",
id: "23",
inip: "93",
endp: "93",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "A",
quote_level: "0",
affected_by_negation: "no",
analysis_list: [
{
tag: "1D--",
lemma: ",",
original_form: ","
}
]
},
{
type: "phrase",
form: "if her hair was still red",
id: "50",
inip: "95",
endp: "119",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
syntactic_tree_relation_list: [
{
id: "34",
type: "isComplement"
},
{
id: "33",
type: "isComplement"
}
],
analysis_list: [
{
tag: "ZE---CIA----",
lemma: "*",
original_form: "if her hair was still red"
}
],
token_list: [
{
form: "if",
id: "24",
inip: "95",
endp: "96",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
analysis_list: [
{
tag: "CSBN7",
lemma: "if",
original_form: "if"
}
]
},
{
type: "phrase",
form: "her hair",
id: "42",
inip: "98",
endp: "105",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
head: "26",
syntactic_tree_relation_list: [
{
id: "40",
type: "isPossessor"
}
],
analysis_list: [
{
tag: "GN-S3---",
lemma: "hair",
original_form: "her hair"
}
],
token_list: [
{
form: "her",
id: "25",
inip: "98",
endp: "100",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
analysis_list: [
{
tag: "SD-SFS3N7",
lemma: "her",
original_form: "her",
sense_id_list: [
{
sense_id: "PRONHUMAN"
}
]
}
],
sense_list: [
{
id: "PRONHUMAN",
form: "her",
info: "semhum=human"
}
]
},
{
form: "hair",
id: "26",
inip: "102",
endp: "105",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
analysis_list: [
{
tag: "NC-S-N6",
lemma: "hair",
original_form: "hair"
}
]
}
]
},
{
form: "was",
id: "27",
inip: "107",
endp: "109",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
syntactic_tree_relation_list: [
{
id: "46",
type: "iof_isSubject"
},
{
id: "43",
type: "iof_isAttribute"
}
],
analysis_list: [
{
tag: "VI-S1ASA-N-N9",
lemma: "be",
original_form: "was"
},
{
tag: "VI-S3ASA-N-N9",
lemma: "be",
original_form: "was"
}
]
},
{
type: "phrase",
form: "still red",
id: "43",
inip: "111",
endp: "119",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
head: "29",
syntactic_tree_relation_list: [
{
id: "27",
type: "isAttribute"
}
],
analysis_list: [
{
tag: "GA---A--",
lemma: "red",
original_form: "still red"
}
],
token_list: [
{
form: "still",
id: "28",
inip: "111",
endp: "115",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
analysis_list: [
{
tag: "ENTPN4",
lemma: "still",
original_form: "still"
}
]
},
{
form: "red",
id: "29",
inip: "117",
endp: "119",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "1",
quote_level: "0",
affected_by_negation: "no",
analysis_list: [
{
tag: "AP-N4",
lemma: "red",
original_form: "red"
}
]
}
]
}
]
}
]
},
{
form: ".",
id: "30",
inip: "120",
endp: "120",
style: {
isBold: "no",
isItalics: "no",
isUnderlined: "no",
isTitle: "no"
},
separation: "A",
quote_level: "0",
affected_by_negation: "no",
analysis_list: [
{
tag: "1D--",
lemma: ".",
original_form: "."
}
]
}
]
}
]
}